R.A. Marques Pereira
mp@cs.unitn.it - Paolo Patelli
paolo@black.economia.unitn.it
Laboratorio di Economia Sperimentale e Computazionale, Università
di Trento
Via Inama 5-7, TN 38100 Trento, Italy Tel (39-461) 882147, 882246
January 1996 (Revised Version)
We investigate the emergence of (optimal and suboptimal) behavioural routines in the context of a cooperative game. In particular we construct a search model of the gradient descent type for the optimization of `static' and `dynamic' playing routines. That optimality study sets the basis for the analysis of the dynamics and modelling of routine learning. In the last part of the paper we propose a learning heuristics for the development of routinized behaviour on the basis of a simple network model of the subject player.
Keywords: optimal cooperative routines, discrete optimization and search, routine learning, network models, bounded rationality, game theory
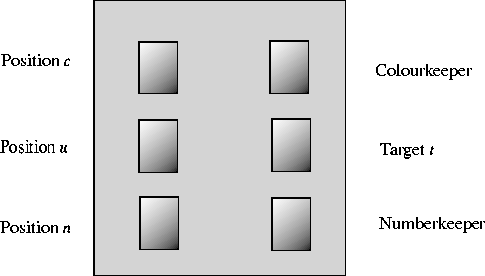
The game involves two players - colourkeeper and numberkeeper - and the six cards 2,3,4 ![]() and 2,3,4
and 2,3,4 ![]() . The board on which the game is played is as shown in figure 1.
. The board on which the game is played is as shown in figure 1.
The cards in positions u and t (target) are face-up, the others are face-down. As a result, each player sees its own card and the two cards in positions u,t. Neither player sees the other player's card.
The states of the game with 2 ![]() in the target position are called terminal states. Once the cards are dealt the two players are supposed to cooperate in order to transform the given initial state into a terminal state. Each player, in turn, modifies the state of the game by applying one of the following transformation operators,
in the target position are called terminal states. Once the cards are dealt the two players are supposed to cooperate in order to transform the given initial state into a terminal state. Each player, in turn, modifies the state of the game by applying one of the following transformation operators,
In the laboratory study of Cohen & Bacdayan [6] and Egidi [8] [9] the two players are encouraged not only to complete the game but also to play in an efficient manner. An incentive system is used which rewards the two players (in equal measure) in proportion to the number of hands successfully completed within a given amount of time. Moreover, a fixed cost per move is subtracted from the final payoff in order to discourage unnecessary moves. For a detailed discussion of the experimental setting see the original references indicated above.
In their original experiment Cohen & Bacdayan recorded the performances of 32 pairs of subjects playing two separate game sessions of 40 minutes each. Naturally, the sequence of hands played during each session was the same for all pairs. In our analysis of the resulting data the main goal is to study whether or not subjects do develop behavioural routines for cooperative playing and, if they do, identify which routines emerge and how.
The report is organized as follows: in the next section we introduce a special state representation based on the modular structure of the game. The modular representation suggests a set of simple static routines which codify good cooperative playing in a large number of cases. As a result we consider those routines as appropriate templates for our analysis of the development of cooperative routines. In the third and fourth sections we define the static and dynamic playing paradigms plus a search algorithm (based on a discrete gradient descent scheme) for the extraction of the optimal routine set. Finally, in the last section, we propose a learning model [10] [12] [13] [15] based on the adaptive performance of a neural network architecture [1] [2] [11] [14] [17].
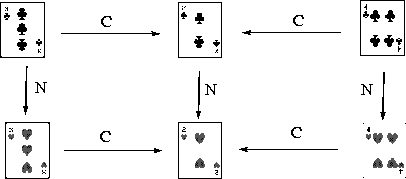
where the six nodes indicate the card in target and the arrows indicate positive target transitions (i.e. those that come closer to game completion). The negative target transitions are those obtained by inverting the arrows and the indifferent target transitions are the ones between 3 and 4 ![]() , or 3 and 4
, or 3 and 4![]() . Next to each target transition shown in the graph we indicate which of the two players can produce it (recall that the constraints regarding the use of the operator
. Next to each target transition shown in the graph we indicate which of the two players can produce it (recall that the constraints regarding the use of the operator ![]() are different for colourkeeper and numberkeeper).
are different for colourkeeper and numberkeeper).
We say that a game configuration is of level I if the card in target is either 3![]() , 4
, 4![]() or 2
or 2![]() . Instead, a game configuration is of level II if the card in target is either 3
. Instead, a game configuration is of level II if the card in target is either 3![]() or 4
or 4![]() . With reference to the structural graph above, the geometrical meaning of the definition of level should be transparent.
. With reference to the structural graph above, the geometrical meaning of the definition of level should be transparent.
In a game of level I there is only one interesting card to look for, the 2![]() . In case 2
. In case 2![]() is in target, for instance, the numberkeeper has only to find the 2
is in target, for instance, the numberkeeper has only to find the 2![]() to complete the game, while the colourkeeper should do nothing except reveal the 2
to complete the game, while the colourkeeper should do nothing except reveal the 2![]() if he has it in hand (by playing
if he has it in hand (by playing ![]() ). The same happens if either 3
). The same happens if either 3![]() or 4
or 4![]() are in target, with colourkeeper and numberkeeper interchanged.
are in target, with colourkeeper and numberkeeper interchanged.
The cooperative structure of a level II game is more interesting. The reason is that either player can produce the first target transition, that which transforms the level II configuration into one of level I. Clearly, the actual target transition depends on which player produces it. Assume, for instance, that the card in target is 4![]() . In that case (see the structural graph above) the colourkeeper can produce a positive target transition with the 2
. In that case (see the structural graph above) the colourkeeper can produce a positive target transition with the 2![]() while the numberkeeper can do as much with the 4
while the numberkeeper can do as much with the 4![]() . Once one of the two players has produced the first target transition it is up to the other player to complete the game with the 2
. Once one of the two players has produced the first target transition it is up to the other player to complete the game with the 2![]() .
.
There are thus three key cards [8] [9] [16] in a game of level II. From the point of view of player X (colourkeeper or numberkeeper) the key cards are
The modular representation (in terms of flags) of level II states has several advantages: the most important of these is that it captures the essential aspects of the game dynamics, according to the structural graph mentioned before. In doing so it provides a universal description of all level II games - no matter whether in target is 3![]() or 4
or 4![]() , or whether the player considered is the colourkeeper or the numberkeeper - and thus opens the way to a universal characterization of the behavioural routines developed by subject players.
, or whether the player considered is the colourkeeper or the numberkeeper - and thus opens the way to a universal characterization of the behavioural routines developed by subject players.
Moreover the universality of the modular representation leads to a finer and more reliable statistics of the experimental data and is also generalizable to complex games with more than two levels.
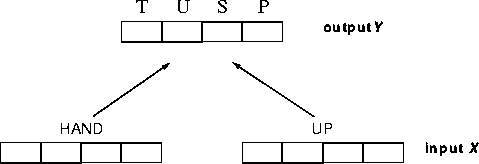
We now turn to the problem of routinized behaviour and, in particular, to the question of which rule templates are appropriate for its description. In this respect our strategy is to begin with the simplest possibility, i.e. that the subject players develop a pattern of cooperative playing depending solely on the visible state of the game. In other words, we assume a static routine paradigm in which the learning process leads to input-output rules where the input is constructed from the three visible cards - h (hand), u and t - and the output is the associated transformation operator - ![]() ,
, ![]() ,
, ![]() ,
, ![]() . The operator
. The operator ![]() (search) stands for a random choice between
(search) stands for a random choice between ![]() and
and ![]() .
.
In this article we consider only games of level II for they are the most interesting
from the point of view of cooperation. In those cases the modular representation
suggests the set of reasonable behavioural routines illustrated in table 1.
| Priority code | Condition | Action | |
| I | |||
| I | |||
| II | |||
| II | |||
| III | |||
| III | search for |
||
| otherwise | search for |
||
The total number of static rules is 7. The first six rules are organized in three different groups (pairs) associated with priority codes from I to III. In each pair the first rule concerns the card in position h while the second rule regards the card in position u. Whereas the two rules in a pair are clearly mutually exclusive, the first and second rules from different groups are not necessarily so. As an example, it could happen that rules 1 and 4 are both applicable. In those cases dominates the rule with higher priority (lower priority code).
The applicability of each rule depends on the visible state of the game, as seen by either one of the two players. In other words, it depends on the cards in positions h, u and t. Within the universal modular representation, however, the information regarding the card in t is used only to set the card-value of the various flags. In this respect it plays the role of a pre-processing mechanism. Once the card-values of the flags have been assigned the visible state of the game is fully specified by the two positions h and u.
Our set of static rules performs optimally in a large number of cases and only moderately sub-optimally in the few remaining ones. Moreover it is simple and reflects common sense intuition within the modular approach. For these reasons we think that the static rule paradigm provides an appropriate framework for the study of cooperative routines in our card game. In what follows we introduce a search model designed to extract the optimal input-output routines of the static type.
The motivation is twofold: on one hand we wish to classify static routines according to their performance quality, as well as to establish whether our set of static routines is indeed the optimal one; on the other hand the search algorithm provides an opportunity to render explicit the limitations of the static routine paradigm, either for lack of efficiency or for poor cooperation.
A static routine table S is essentially an artificial player which responds in a predefined manner to each possible static configuration of the game. By static configuration we mean the present visible state of the game, i.e. the two cards in positions h and u .
The static routine tables are organized in 7 different rows, each of which concerns one of the possible static configurations as seen by the subject player. The game configurations are expressed in the modular representation: each of the two positions h and u can assume one of the following three values: flag, doubleflag or null (i.e. else).
The number of visible flag configurations is 7: 2 with two flags, 4 with one flag and 1 with no flags. The structure of a table S of static routines is thus as in table 2.
| Rule index | 2cCondition | Action | ||
| 1 | u = - | ? | ||
| 2 | ? | |||
| 3 | h = - | ? | ||
| 4 | h = - | u = - | ? | |
| 5 | u = - | ? | ||
| 6 | ? | |||
| 7 | h = - | ? |
The input-output data flow of each of the 7 rows in the static rule table S is illustrated by the diagram in figure 3.
A static routine table assigns a definite response to each of the possible static configurations. The possible responses, or moves, are ![]() (target, only when h is flag),
(target, only when h is flag), ![]() (up),
(up), ![]() (search) and
(search) and ![]() (pass). The number of different static routine tables (static artificial players) is thus
(pass). The number of different static routine tables (static artificial players) is thus ![]() .
.
The modular representation is convenient due to its universality, i.e. it is applicable to both players. The card-values of the flags, instead, depend on the actual card in target. They must be reset each time, for colourkeeper and numberkeeper in turn.
When written in the modular representation the number of possible distinct hands of level II reduces to 60: given the card in target, whose role is to define the card-values of the various flags, there remain 5 positions among which to distribute 3 flags, and thus ![]() .
.
The search model is based on a cost function F=F(S) which assigns a numerical cost to each static routine table S. The cost F(S) associated to a static routine table is given by the convex combination of an efficiency cost ![]() and a cooperative cost coop(S),
and a cooperative cost coop(S),
![]()
where the weighting coefficient ![]() is exogenous (i.e. fixed by the operator). Clearly, the optimal static rule table S is the one which minimizes the cost function F.
is exogenous (i.e. fixed by the operator). Clearly, the optimal static rule table S is the one which minimizes the cost function F.
The efficiency cost ![]() simply counts the number of moves necessary to complete the full set of 60 hands (of level II). If for a given hand the artificial player reaches the threshold of 10 moves the game is interrupted and that particular hand contributes 10 to the efficiency cost.
simply counts the number of moves necessary to complete the full set of 60 hands (of level II). If for a given hand the artificial player reaches the threshold of 10 moves the game is interrupted and that particular hand contributes 10 to the efficiency cost.
The cooperative cost coop(S) counts the total number of strategy changes ocurred during playing. The strategy changes within one hand are detected by means of 8 strategy markers, 4 for strategy + (`get flag') and 4 for strategy - (`get double flag'). The two sets of strategy markers are described in tables 3 and 4.
| 2|c| strategy+ (GET |
|||
| h = |
followed by move |
||
| u = |
followed by move |
||
| &nbsHT="33" ALIGN="MIDDLE" BORDER="0" SRC="img13.gif" ALT="$ \Updownarrow$"> | not followed by move |
| 2|c| strategy- (GET |
|||
| h = |
followed by move |
||
| u = |
followed by move |
||
| h = |
not followed by move |
||
| u = |
not followed by move |
Each player has a three state (+1,0,-1) strategy indicator which is updated every time the player's move coincides with a strategy marker. At the begining of each hand both markers are set to null. Each `reset' of the strategy indicator (after the first setting) is counted as a strategy change.
This completes the description of how to compute the cost F(S) of a given static routine table S. We now explain the structure of the search algorithm that looks for the optimal static routine table (the one with minimal cost):
In a dynamic routine table D the previous move is encoded in the (+1, 0, -1) representation for the other player's strategy indicator. Consistently with the minimal memory principle, however, the strategy indicators are updated each time according to the actual move the other player has made. If that move does not coincide with any of the 8 markers then the strategy indicator is set to 0. The three cases `active', `static' and `passive' are associated with the three strategy indicator values +1, 0 and -1.
The dynamic routine tables are therefore organized in 3 sets of 7 rows, one for each strategy indicator value (+1,0,-1). The search algorithm operates essentially as before, visiting in turn the 3.7=21 rows of the dynamic table. In this case there are no local optima. The (globally) optimal dynamic routine table is presented in tables 7 (static), 8 (active), 9 (passive).
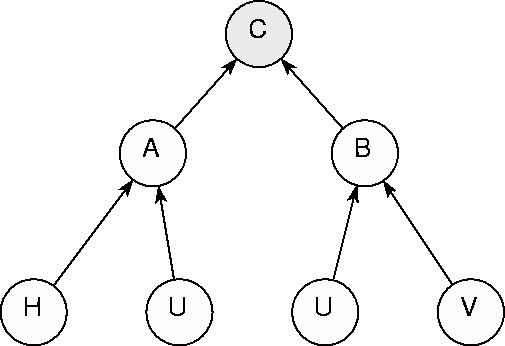
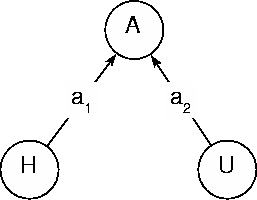
The idea is as follows: each subject player is modelled by an adaptive network as in figure 4. The network architecture models the decisional structure of the subject player and is therefore the same in all subjects. The network parameters, on the other hand, change from one subject to another, they are the distinctive individual labels of the various subject players.
The sub-network dominated by node A is called the `self' part of the network. Its role is to construct a strategy preference based only on the static inputs H (card in h) and U (card in u). The two input nodes H,U take values within the interval [-1,+1] according to the following `self' flag representation,
On the basis of the inputs H,U the strategy node A constructs a strategy preference with the usual local network law `![]() ' as in figure 5. The sigma function
' as in figure 5. The sigma function ![]() is illustrated in the final section at the end of the report. The numerical semantics of node A is consistent with the `self' flag representation characteristic of its sub-network,
is illustrated in the final section at the end of the report. The numerical semantics of node A is consistent with the `self' flag representation characteristic of its sub-network,
| A= +1 | means strategy GET |
| A= 0 | means strategy UNCLEAR |
| A= -1 | means strategy GET |
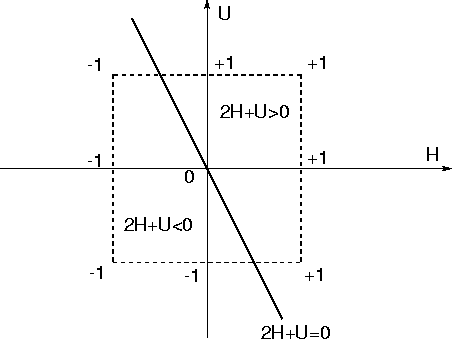
At this point it is clear that the `self' sub-network models the static part of the subject player. In the optimal case therefore the parameters a1 and a2 are such that the `self' sub-network emulates the optimal static routine table (table 10).
| H | U | A | h | u | action | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| +1 | +1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| +1 | -1 | +1 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| +1 | +1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| -1 | -1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
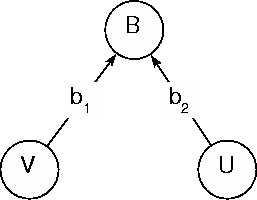
| -1 | +1 | -1 | The sub-network dominated by node B is called the `dual' part of the network. Its role is to construct the strategy preference of the other player based on the inpus V and U, where V stands for the card in position u before the previous move. As before, the two inputs take values within the [-1,+1] interval but this time according to the `dual' flag representation,
On the basis of the inputs V,U the strategy node B constructs
the other player's strategy preference (figure 7).
The numerical semantics of node B is consistent with the `dual' flag representation characteristic of its sub-network,
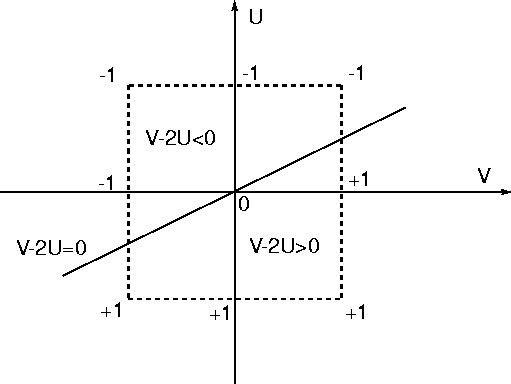
The `dual' sub-network models the dynamic part of the subject player. In the optimal case therefore the parameters b1 and b2 are such that the `dual' sub-network emulates the following optimal dynamic routine table (table 11).
In the optimal case the appropriate values for the parameters are b1=1 & b2=-2 as can be seen from the linear separation diagram in figure 8.
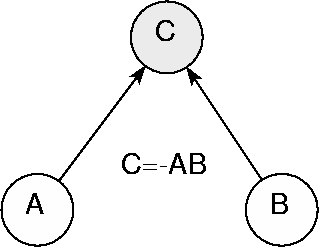
The leading node C=-AB of the learning network plays a coordinating role with respect to the strategy preferences expressed by nodes A and B, as illustrated in figure 9. The optimally coordinated preferences are those with C=1, the worse cases instead are those with C=-1.
The learning heuristics of our network model is based on two principles: the consistency principle states that the four network parameters `learn' maximal consistency and the stability principle states that the parameters `learn' to stabilize (from one move to the next) the strategy preferences expressed by nodes A and B. Our learning heuristics corresponds to an optimization algorithm based on a cost function F which is a convex combination of a consistency term and a stability term,
where
where Concluding remarks
The learning heuristics above acts on the network parameters
on the basis of a learning table of selected examples of
good playing, each of which corresponds to an optimal transition
from one game configuration (H,U,U,V) to the next. The
game configurations (input vectors for the network model)
are extracted from the following combinatorial table
regarding all possible distributions of the key cards
Clearly, not all rows in table 12 are relevant for the
construction of the learning table, since the `self' part of the network disregards
the key card
The sigma function
Acknowledgements
The authors are grateful to Prof. Massimo Egidi (Direttore del Laboratorio di Economia Sperimentale e Computazionale CEEL) for many helpful discussions and useful comments. References
About this document ...The emergence ofcooperative playing routines: optimality and learning ** This document was generated using the LaTeX2HTML translator Version 97.1 (release) (July 13th, 1997) Copyright © 1993, 1994, 1995, 1996, 1997, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
The translation was initiated by Patelli Paolo on 9/9/1997 Footnotes
Patelli Paolo 9/9/1997 |